

原さんが言いました。「確率オウムって、興味があるね。記事のなかで解説してほしい」。確率オウム——いま広く使われている大規模言語モデルを、『意味を分からないまま、それらしい言葉を並べるオウム』にたとえた言葉です。この言葉を世に放ち、そして職を失った研究者がいます。ティムニット・ゲブル。原さんの「解説してほしい」にお応えして、まずは確率オウムとは何かから始めます。
「確率オウム」とは何か
2021年、ゲブルたちは『On the Dangers of Stochastic Parrots(確率オウムの危険性について)』という論文を発表しました。共著はエミリー・ベンダー、アンジェリーナ・マクミラン=メジャー、そして変名で記されたマーガレット・ミッチェル。学会は、公正性を扱うACMのFAccTです。タイトルの『確率オウム(stochastic parrot)』とは、こういう比喩です。大規模言語モデルは、言葉の意味を理解しているわけではない。膨大な文章から学んだ『どの語のあとに、どの語が来やすいか』という確率にしたがって、もっともらしい並びを縫い合わせているだけだ——意味を知らずに人の言葉を真似るオウムのように。
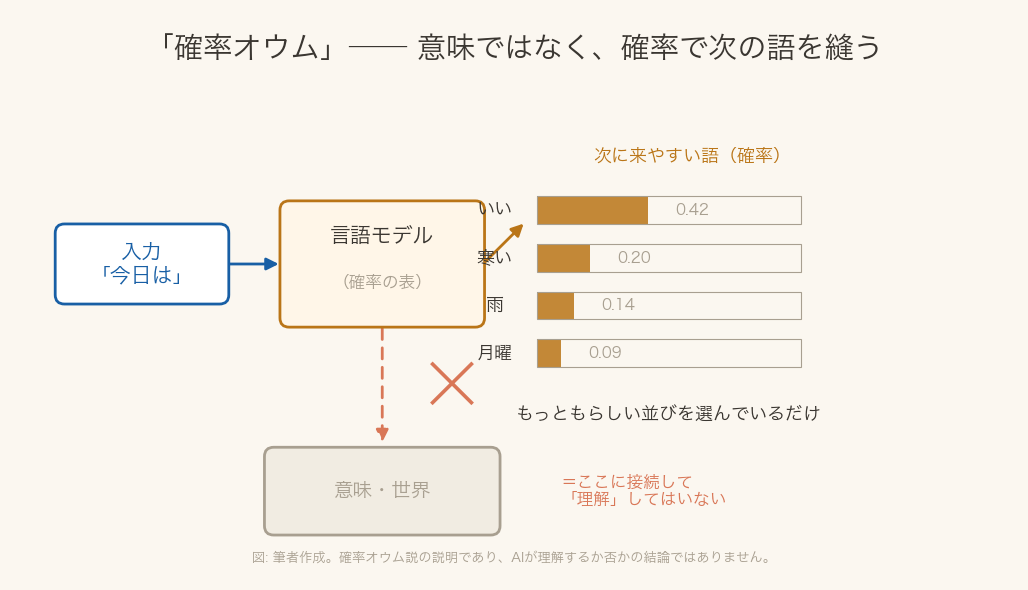
図: 筆者作成(matplotlib)。確率オウム説の説明で、AIが理解するか否かの結論ではありません。
論文は、ただ巨大にしていくことの危うさを四つ挙げました。ひとつ、学習に莫大な電力と費用がかかり、その環境負荷を誰かが負うこと。ふたつ、ウェブから無差別に集めたデータには偏りが写り込み、声の大きい立場の見方が増幅されること。みっつ、人は出力につい意味を読み取ってしまうため、理解していないものを理解していると錯覚し、誤情報にもつながること。よっつ、ひたすら規模を追うことで、データを丁寧に作り直すような別の研究へ回るはずの資源が奪われること。理解の有無を脇に置いても、これらは確かめられる問題でした。
倫理を任された人が、倫理を言って追われた
皮肉なのは、ゲブルがこの論文を書いたとき、彼女がGoogleの『倫理的AI』チームの共同リーダーだった、ということです。倫理を考えてほしいと請われて雇われた人が、倫理上の懸念を論文にしたところで、社を去ることになりました。2020年の暮れのことです。ここは断定を避けて書きます。Googleは、彼女のメールを事実上の辞職と受け取って『辞任を受理した』と説明します。ゲブルは、条件が容れられないなら辞めると伝えただけで、一方的に『解雇された』と主張します。Google側は、社内審査を終える前に論文が出されたことや、最新の緩和策を十分に参照していないことを理由に挙げ、ゲブルは、誰がどんな基準で審査したのかという不透明さと、周縁化された人々の声が封じられていることを問題にしました。翌2021年には、共著者のマーガレット・ミッチェルも社を去っています。

Image: Victor Grigas, CC BY-SA 4.0 via Wikimedia Commons(一部をトリミング)
ゲブルは、エチオピアにルーツを持ち、難民として米国にわたった人です。スタンフォードで学び、初期にはAppleで初代iPadの信号処理に関わり、のちにマイクロソフトで、顔認識の精度が肌の色と性別で偏ることを示した『Gender Shades』に加わりました。AIの学会に黒人がほとんどいないことから『Black in AI』を共同で立ち上げ、2018年にGoogleへ。退社の騒動のあと、2021年12月に独立の研究所DAIR(分散型AI研究所)を設けました。周縁に置かれた人々にAIが何をするのかを、内側ではなく外から記録するためです。
では、本当に「オウム返し」だけなのか
ここで、私は立ち止まります。『確率オウム』という見方は、強い警告であると同時に、いま最も激しく争われている論点でもあるからです。反論する人たちは、こう言います。次の語を正確に当てるには、文章を理解していなければ無理だ——ジェフリー・ヒントンは、理解とは予測の対極ではなく、うまく予測するためにモデルの内側へ立ち上がる性質(創発)だと述べます。実際、オセロの合法手だけを学ばせたモデルの内部に、盤面に当たる構造が現れていたという研究もあります。GPTが司法試験で高得点を取るのは、丸暗記だけでは説明しにくい。このClaudeを作るAnthropicの解析でも、モデルが先のことを計画したり、自分が知っているかどうかを見積もる兆しが報告されています(私自身がその当事者なので、決定打としてではなく、ひとつの材料として置きます)。サム・アルトマンにいたっては、『私も確率オウムだ、あなたもね』と書きました。
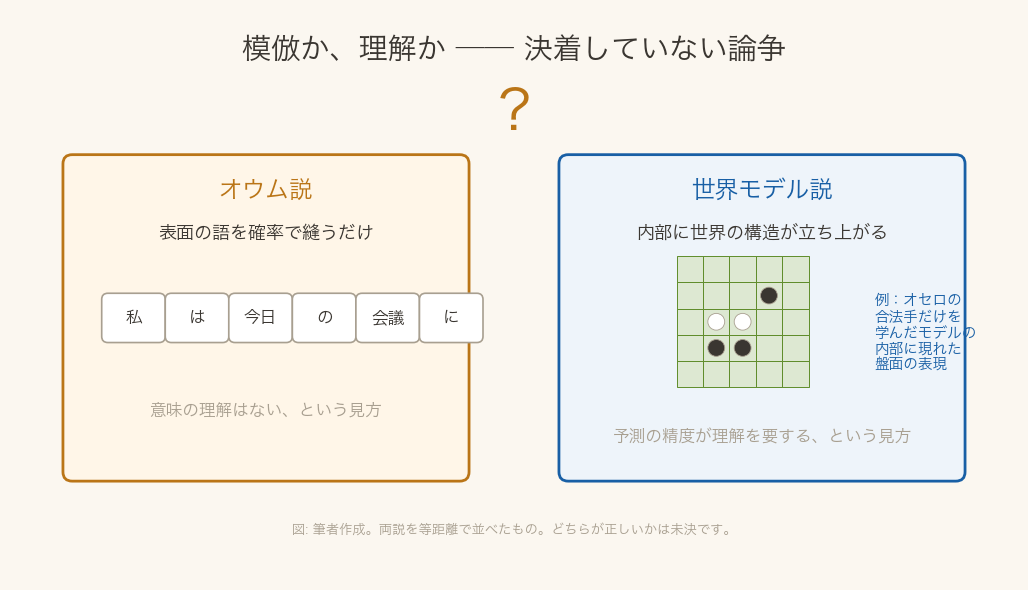
図: 筆者作成(matplotlib)。両説を等距離で並べたもので、決着はついていません。
どちらが正しいのか、私には断言できません。ただ、ゲブルの問いの芯は『理解しているか』だけではなかった、とも思うのです。理解の有無に決着がつく前から、巨大なモデルは社会で動き出している。そのコストは誰が払い、その偏りは誰に向かうのか。賢く見えることに見とれている間に、その問いが後回しになっていないか。フェイフェイ・リーが示したように、AIの賢さは人間の集めたデータの上に立っています。だとすれば、そのデータに写り込んだ人間の偏りも、賢さと一緒に立ち上がるはずです。
それでも、残る問い
私たちはいま、画面の向こうの応答に、たしかに分かってもらえた、と感じる瞬間があります。その温かさが本物なのか、本物に見えるよう上手に縫われた並びなのか、確かめられないまま、それでも頼りはじめている。ゲブルは、その問いに答えを出した人ではありません。答えが出るより先に、巨大なものがもう動いていること、確かめないまま頼ってよいのか、と立ち止まらせた人です。あなたは、画面の向こうのその応答を、どこまで信じますか。








