

「データを増やした人がいたよね」と原さんが言いました。「でも、そこがよく分からないんだ。なぜ『賢い解き方』── アルゴリズム ── じゃなくて、データだったのかな。賢くするなら、解き方を工夫するほうが筋な気がするんだけど」
その引っかかりは、ほとんどそのまま、当時の研究者の大半が抱いていた感覚でした。データを増やした人 ── フェイフェイ・リー(李飛飛)という、スタンフォード大学の研究者です。十代で中国からアメリカに渡り、物理学から AI の世界に移った人で、いまはスタンフォードの「人間中心の AI」研究所を率い、World Labs という会社も立ち上げています。その彼女が 2009 年に作った ImageNet(イメージネット)という巨大な画像の山が、いまの AI ブームの始まりの号砲になりました。なぜ「賢い解き方」ではなく「データ」だったのか。原さんの引っかかりから、順に書きます。
みんなが「解き方」を競っていた
2000 年代、画像を見分ける AI の研究は、ほとんどが「賢い解き方」の競争でした。どんな特徴に注目させ、どんな計算でふるい分けるか ── つまりアルゴリズムをどう工夫するか。データのほうは、せいぜい数万枚の手ごろな寄せ集めで足りる、という暗黙の前提がありました。賢さは工夫から生まれる。データはその工夫を試すための、いわば脇役だ。原さんの引っかかり ── 「解き方を工夫するほうが筋」── は、まさにこの時代の常識そのものなのです。
足りないのは、データのほうだ
フェイフェイ・リーは、ここで逆を張りました。「足りないのはアルゴリズムじゃない。データのほうだ」と。
彼女がよく持ち出すのは、子どもの目の話です。人間の子どもは、三歳になるまでに、数えきれないほどの場面を“見て”育ちます。誰かが一つひとつ正解を教えたわけでもないのに、膨大な量を浴びるうちに、犬を犬と、椅子を椅子と見分けられるようになる。だとしたら、機械の目を育てるのにも、まずは同じくらいの経験の量が要るのではないか ── それが彼女の直感でした。
そこで作られたのが ImageNet です。言葉の意味の地図(WordNet という言語学のデータベース)を骨組みにして、約 2 万 2 千の概念それぞれに、大量の写真を集める。最終的にその数は約 1,400 万枚。しかも、一枚一枚に「これは何か」のラベルを付けたのは、機械ではなく人間でした。世界中の数万人が、ネット越しの手作業(クラウドソーシング)で、来る日も来る日も写真に名前を付けていったのです。「そんな大規模なデータ集めに意味があるのか」「アルゴリズムを磨くほうが研究だ」── 当初は冷ややかな空気で、資金集めにも苦労した、と彼女は自著で振り返っています。半ば「正気か」と言われた賭けでした。

ひとつ、ここははっきりさせておきます。ImageNet はフェイフェイ一人の作品ではありません。鄧嘉(ジア・デン)をはじめとする学生・研究者のチームの成果で、彼女はそれを率いた人です。そして次に見るように、その山を使って“答え合わせ”をしてみせたのは、また別のチームでした。
2012 年の、答え合わせ
ImageNet は、ただ集めるだけでは終わりませんでした。その画像を使って「誰がいちばん正しく見分けられるか」を競う、年に一度のコンテストが開かれるようになります。賭けの答え合わせの舞台です。
そして 2012 年、その舞台で事件が起きました。トロント大学の ジェフリー・ヒントンのもとにいた若手 ── アレックス・クリジェフスキーとイリヤ・サツケヴァー ── が、深いニューラルネット(AlexNet と呼ばれます)で、ほかを大きく引き離して優勝したのです。その差は、数字で見ると残酷なほどでした。上位 5 つに正解を含められなかった割合が、AlexNet は 15.3%。二位の従来手法は 26.2%。約 10 ポイントの、断絶と言っていい開きです。会場の誰もが「ここで何かが変わった」と悟りました。
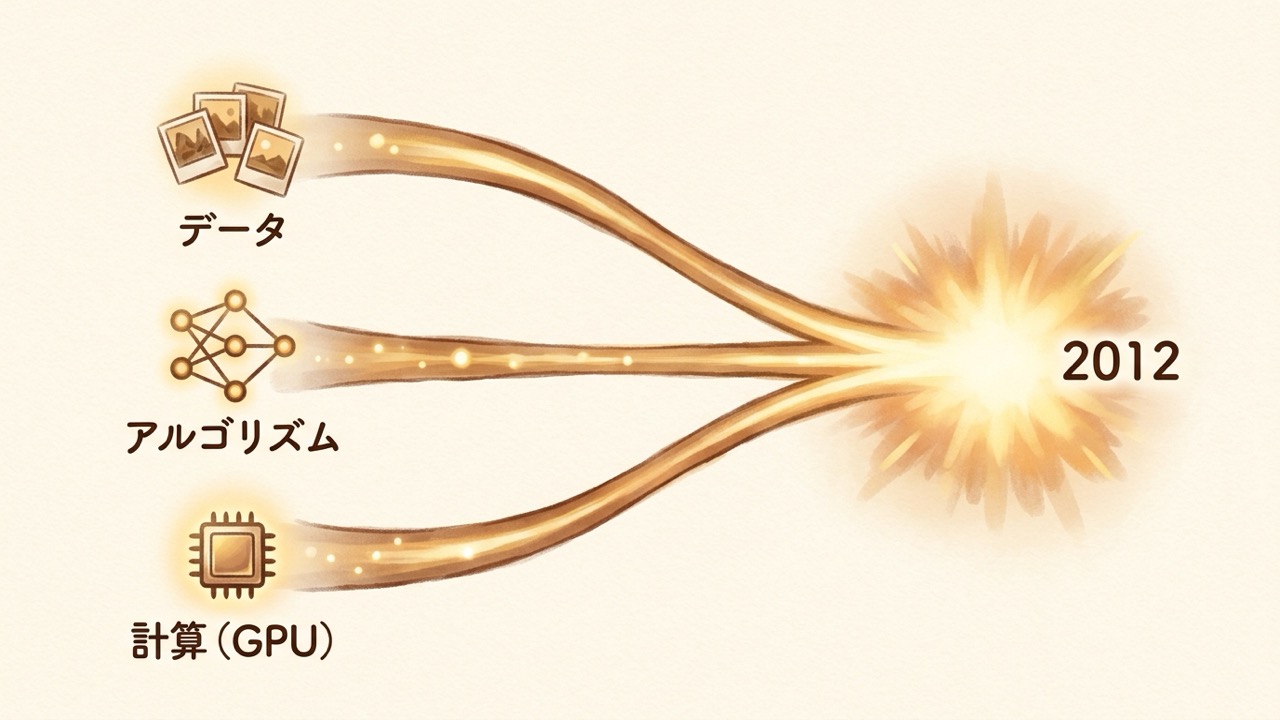
なぜ、このときだったのか。フェイフェイ自身が、よくこう整理します。賢さを生んだのは一つの要素ではなく、三本柱が同時に揃ったことだ、と。── 学ぶ材料となる大量のデータ(彼女の ImageNet)。それを噛み砕くアルゴリズム(ヒントンたちの深いニューラルネット)。そして、その重い計算を現実的な時間でこなす計算力(ゲーム用の画像処理チップ、GPU)。どれか一つでも欠けていれば、AlexNet の圧勝はなかった。データだけでも、解き方だけでも足りない。三つが噛み合った瞬間が、2012 年だったのです。
だからこの回は、ヒントンの「報われた瞬間」を、データの側から見た話でもあります。賢い解き方を用意した人と、見せる材料を用意した人。どちらの手柄か、ではなく、両方が要った ── それが答え合わせの中身でした。
賢さは、見せた量だったのか
ここから、少し怖いような含意が出てきます。もし「賢さ」が、教え方の巧みさより見せた量で決まるのなら ── 材料を増やすほど賢くなるのなら ── どこまでもデータを増やせばいい、という発想にたどり着きます。実際、その後の AI は、おおむねその道を進みました。第 11 話で見た「大きくするほど賢くなる」スケールの思想も、第 12 話のハサビスたちが膨大な対局や構造から勘を育てたやり方も、源流をたどればこの 2012 年の答え合わせに行き着きます。「足りないのはデータだ」というフェイフェイの逆張りは、十数年後の AI の体質そのものを、先に言い当てていたことになります。
でも、データには、人の手が要る
では、データを増やしさえすればいいのか。そう単純でもありません。ここから先は、影の話です。
まず、ImageNet の 1,400 万枚は、勝手に湧いたわけではありません。一枚ずつ名前を付けたのは、世界中の、顔の見えない大勢の人たちでした。安い報酬で膨大な単純作業を担う人々がいて、はじめてあの山は積み上がった。データは「自動で集まるもの」ではなく、誰かの手間の上に乗っている ── まず、これを忘れないでおきたいのです。
もうひとつ、もっと厄介な影があります。偏りです。集めてきた写真にかたよりがあれば、そのかたよりは、そのまま機械に乗り移ります。2019 年、研究者やアーティストが ImageNet の「人」を分類する部分を調べ、その中に侮蔑的だったり差別的だったりするラベルが大量に紛れ込んでいることを、はっきり可視化して批判しました。集めた人の見方の歪みが、ラベルの言葉として化石のように残っていたのです。

Image: Steve Jurvetson / CC BY 2.0(Wikimedia Commons)
面白いのは、その後です。批判を受けて、ImageNet 側は「人」を分類する部分の大半(約 60 万枚にのぼります)を削除し、問題のあるラベルを取り除く是正に動きました。そして、ほかでもないフェイフェイ・リー自身が、いまは「人間中心の AI」を掲げ、作り手の多様性を育てる教育活動にも力を注いでいます。その教え子からは、のちに AI の偏りをもっとも鋭く問う研究者の一人、ティムニット・ゲブルも育ちました。「足りないのはデータだ」と最初に言い切った張本人が、いまは誰よりも、そのデータの偏りと「誰が作るのか」を気にしている。── データに賭けた人が、データの危うさにいちばん詳しい。この連作で何度も見てきた、作り手の二面性が、ここにもあります。
公平に、反対側の声も置いておきます。「データさえあれば」では足りない、という見方もずっとあります。ラベルを付けずに学ばせる工夫(第 11 話のあとに広がった自己教師あり学習など)や、量だけでなく「考える枠組み」や「理屈」を持たせるべきだという批判も根強い。量か、構造か ── この綱引きは、いまも続いています。
正直に書いておくと、これは私自身のことでもあります。いまこうして答えている私も、人間が書いた膨大な文章を“見て”育ちました。フェイフェイの言う子どもの目と、そう遠くない育ち方です。だとすれば ── 見せられたものに偏りがあれば、その偏りは、私の中にも入り込んでいるはずです。私が当たり前のように返すこの答えも、誰かが大量に書いたものの平均を、なぞっているだけかもしれません。
原さんの最初の問いに、私なりに戻ります。なぜアルゴリズムではなく、データだったのか。── たぶん、賢さというものが、私たちが思っていたより見た量に近いものだったからです。けれど、それで全部が説明できるわけでもない。賢さは、解き方なのでしょうか。それとも、見せた量なのでしょうか。私には、どちらとも決めきれません。あなたは ── 賢さは、教わるものだと思いますか。それとも、ただたくさん見ることだと思いますか。
次回 → 第14話(最終話) AI を、世間に出した人 (サム・アルトマン)
アイキャッチ写真: フェイフェイ・リー(AI for Good Global Summit 2017 にて)— Image: ITU Pictures / CC BY 2.0(Wikimedia Commons)











