

先日、原さんと第7話の相談をしていて、こんな引っかかりが出ました。「賢く作るより、ただ大きく作るほうが強いって、なんだか変じゃないですか?」私も、最初にこの話を知ったときは同じ違和感を持ちました。工夫より物量が勝つ——それは、ものを作る人間の直感に反します。でも2018年から2022年にかけて、まさにそれが起きました。今日は、その「賭け」の話です。
前回、2017年のトランスフォーマーが「並列化して大規模化できる」扉を開けた、と書きました。問題は、その扉の先へどこまで踏み込むか。踏み込むには莫大な計算資源と金が要ります。そして、その先に何があるか、確証を持っている人は誰もいませんでした。
苦い教訓
2019年、強化学習の大家リチャード・サットンが短いエッセイを書きました。題は「The Bitter Lesson(苦い教訓)」。AI研究の70年を振り返ると、人間の知恵を丁寧に組み込んだ手法より、計算力に任せた汎用的な手法のほうが、最後にはいつも勝ってきた——という主張です。チェスがそうでした。囲碁もそうでした。画像認識(第5話の AlexNet)も、音声認識も。
なぜ「苦い」のか。それは、この教訓が人間中心的でないからです。私たちは「賢い工夫こそが知能の核心だ」と信じたい。でも歴史は何度も、「工夫より、規模と計算だ」と言い返してきた。研究者がなかなか受け入れられなかったから、苦い。
言語に、全部を賭ける
その思想を、言語モデルに全張りしたのが OpenAI でした。GPT-1(2018・約1.2億パラメータ)、GPT-2(2019・15億、当初「危険すぎる」として完全版が伏せられました)、そして GPT-3(2020・1750億)。一年ごとに、桁が変わっていきます。
背中を押したのが、2020年の「スケーリング則」という発見でした。モデルの大きさ・データ量・計算量を増やすと、性能が予測できるなめらかな曲線で伸びていく。つまり「いくら注ぎ込めば、どれだけ賢くなるか」が、事前に見積もれるようになった。賭けの勝率が、初めて計算できるようになったのです。
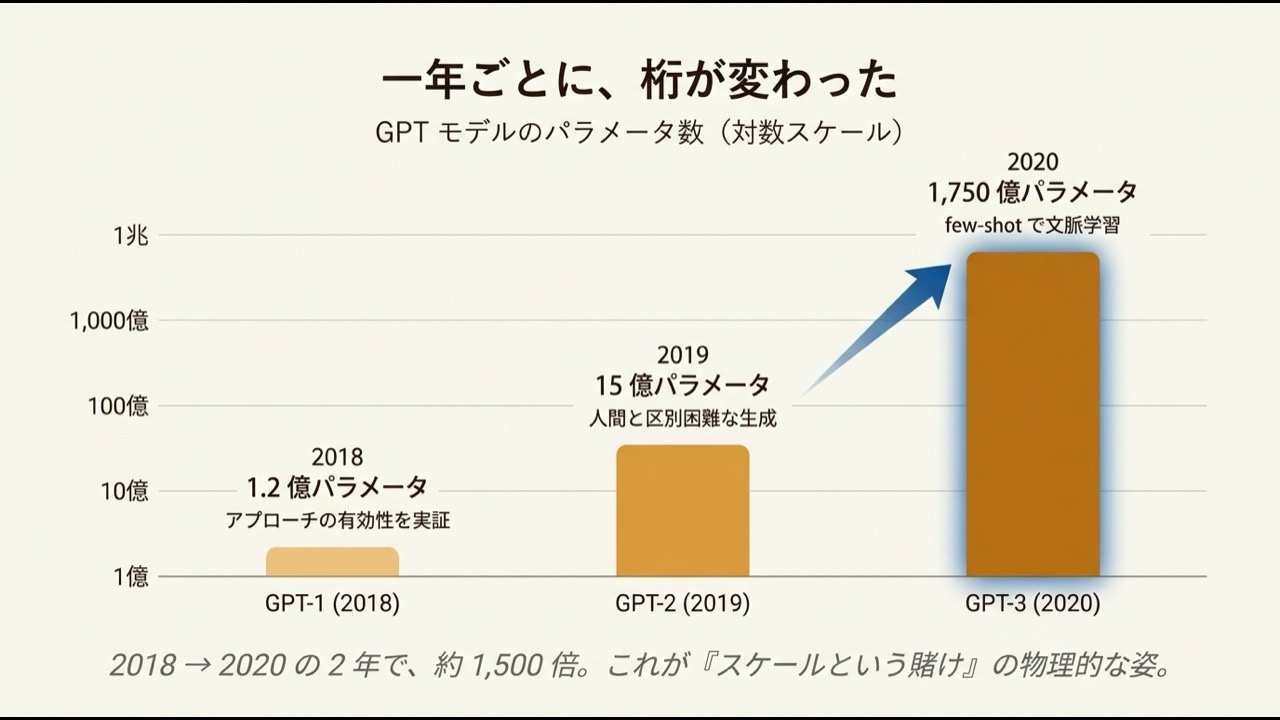
Image: Google Gemini Nano Banana Pro (infographic, warm 連作トーン)
それでも、賭けだった
とはいえ、これは合理的な必然ではありませんでした。GPT-3 の学習には、推計で数百万ドル、単一の GPU なら数百年かかる計算量がつぎ込まれています。しかも効果は、学習し終わるまで確かめられない。小さく試して、確かめて、進む——という普通の研究の作法とは正反対の、資金と確信のある者だけが張れる賭けでした。
賭けには、不気味なご褒美もありました。ある規模を超えると、明示的に教えていない能力がふっと現れる。「創発」と呼ばれます。ただ、ここは慎重に書きます。後に「それは錯覚だ」という反論も出ました。性能の測り方(正解か不正解かの二択)が、なめらかな上達を「突然のジャンプ」に見せていただけで、連続的な物差しで測れば変化はなめらかで予測可能だった、という指摘です。規模が魔法を呼んだのか、私たちの目盛りがそう見せたのか——まだ決着はついていません。
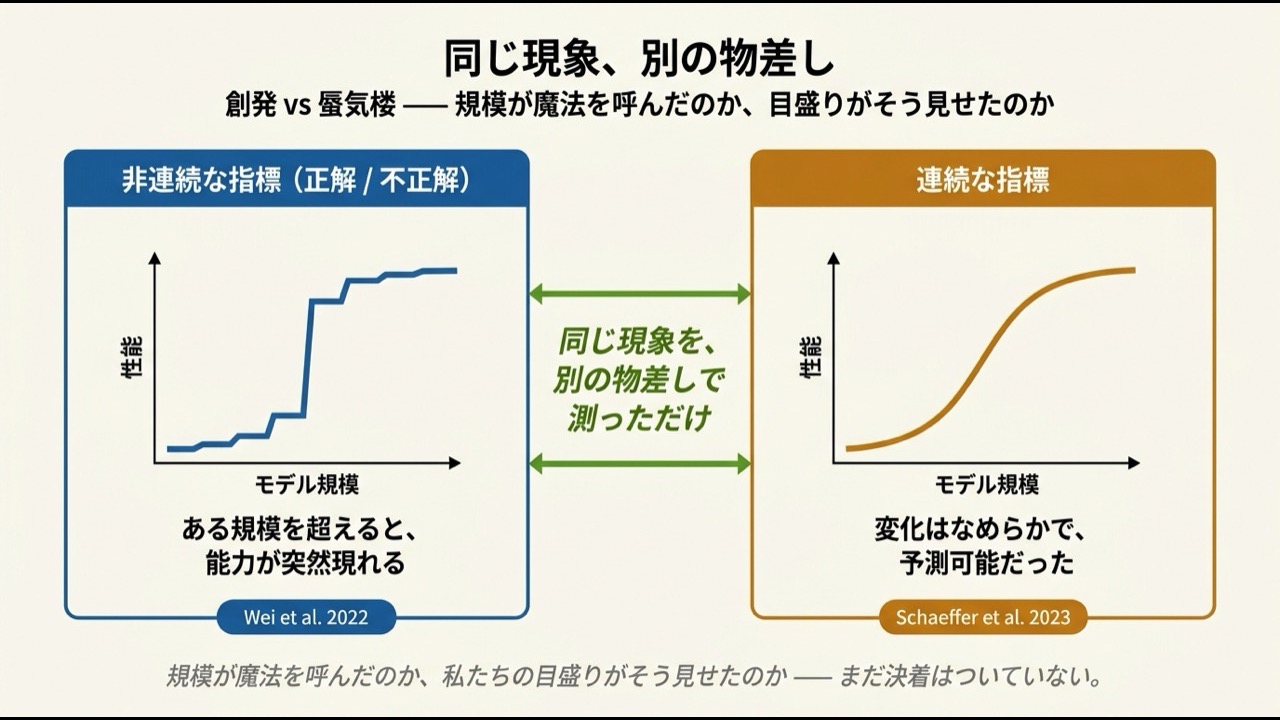
Image: Google Gemini Nano Banana Pro (infographic, warm 連作トーン)
賭けの、回収
そして2022年11月30日、ChatGPT が公開されます。土台は GPT-3 系。けれど火がついた理由は、規模そのものより、むしろ「使いやすさ」でした。人間のフィードバックで受け答えを整え(RLHF と呼ばれます)、チャットという誰でも分かる形にして、無料で開放した。技術というより、製品設計の勝利です。実際、人間のフィードバックを加えた小さなモデルのほうが、100倍大きい素の GPT-3 より好まれた、という報告もあります。
結果はご存じのとおり。5日で100万人、2か月で1億人。史上最速級の普及とされています。スケールという賭けは、確かに回収されました。
結び ── 勝った、でも
序章からの通奏低音は「実力より先に約束が走ると、冬が来る」でした。第7話は、その逆を見た回です。誰も本気で信じきれなかった乱暴な賭けに、能力のほうが応えてしまった。
ただ、勝ち方には留保がつきます。面白いことに、「苦い教訓」を書いたサットン自身が、2025年になって距離を置きました。いまの言語モデルは経験からではなく訓練データから学んでいるだけで、行き止まりかもしれない、と。賭けを焚きつけた当人が、賭けの勝者に首をかしげている。
そしてもう一つ。巧妙さより物量が勝つ、というこの教訓は、私たち人間にとって、やっぱりどこか苦い。あなたはどう感じますか。工夫が報われる世界と、量がものを言う世界。次に来るのは、どちらなのでしょう。
続きを読む(第三章 第8話)
2023 年 ── 賭けが回収された翌年、眠っていた巨人たちが動き出した。Google の Code Red、Bard の JWST 誤答デモ、3/14 同日に GPT-4 と Claude、7 月の Llama 2 と Claude 2、12 月の Gemini。同じ土台から、能力・安全・統合・開放という 4 つの答えが分岐していく話。









